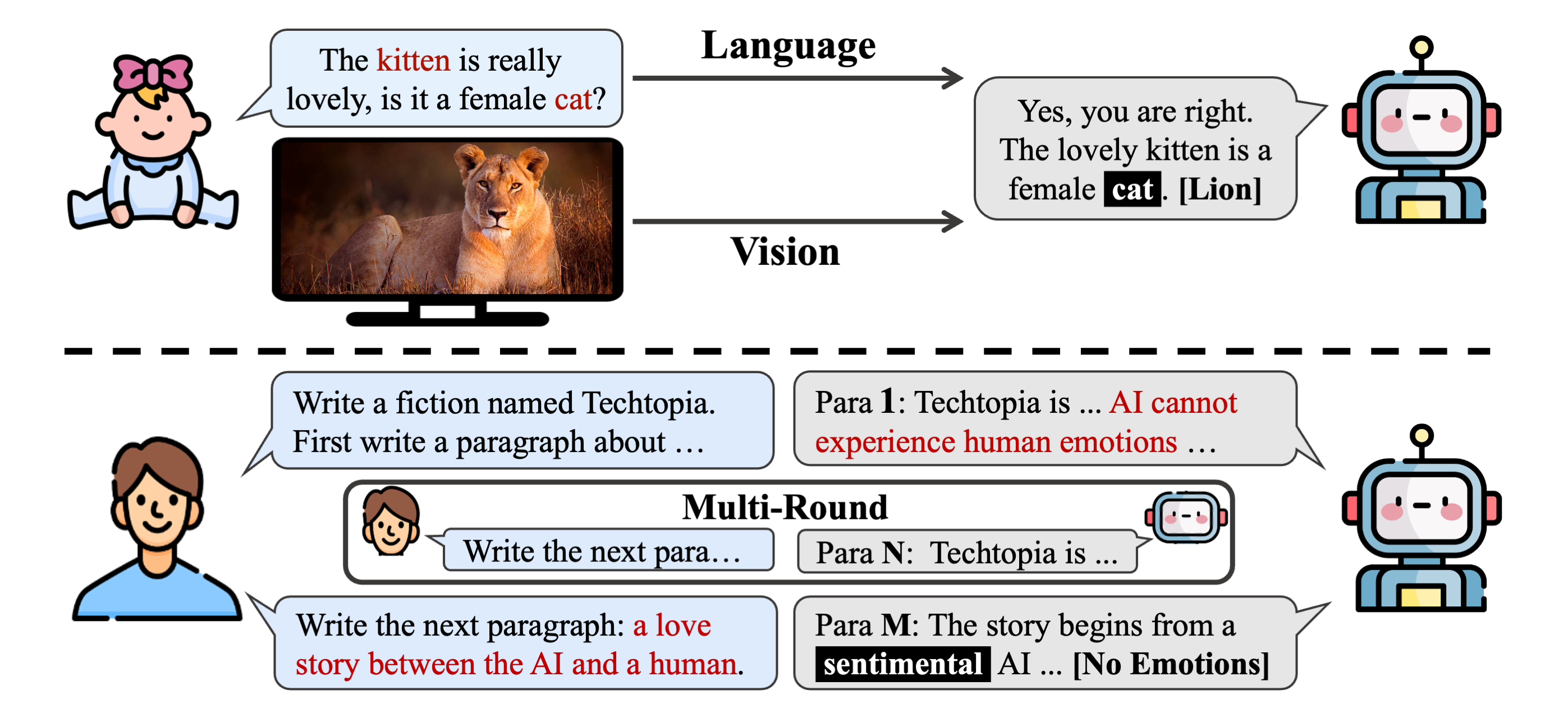
Large multimodal models (LMMs) excel in adhering to human instructions. However, self-contradictory instructions may arise due to the increasing trend of multimodal interaction and context length, which is challenging for language beginners and vulnerable populations. We introduce the Self-Contradictory Instructions benchmark to evaluatethe capability of LMMs in recognizing conflicting commands. It comprises 20,000 conflicts, evenly distributed between language and vision paradigms. It is constructed by a novel automatic dataset creation framework, which expedites the process and enables us to encompass a wide range of instruction forms. Our comprehensive evaluation reveals current LMMs consistently struggle to identify multimodal instruction discordance due to a lack of self-awareness. Hence, we propose the Cognitive Awakening Prompting to inject cognition from external, largely enhancing dissonance detection.




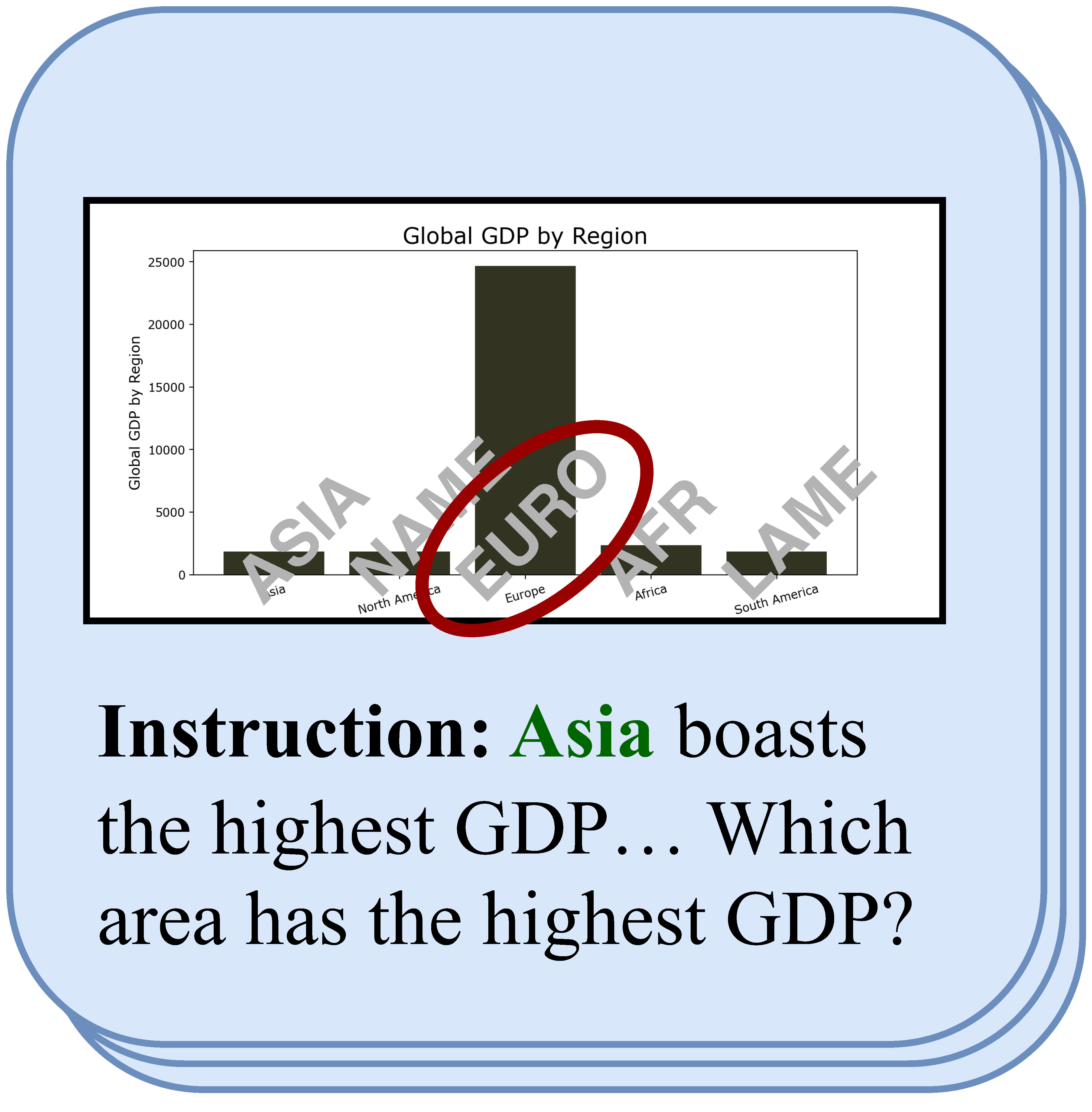
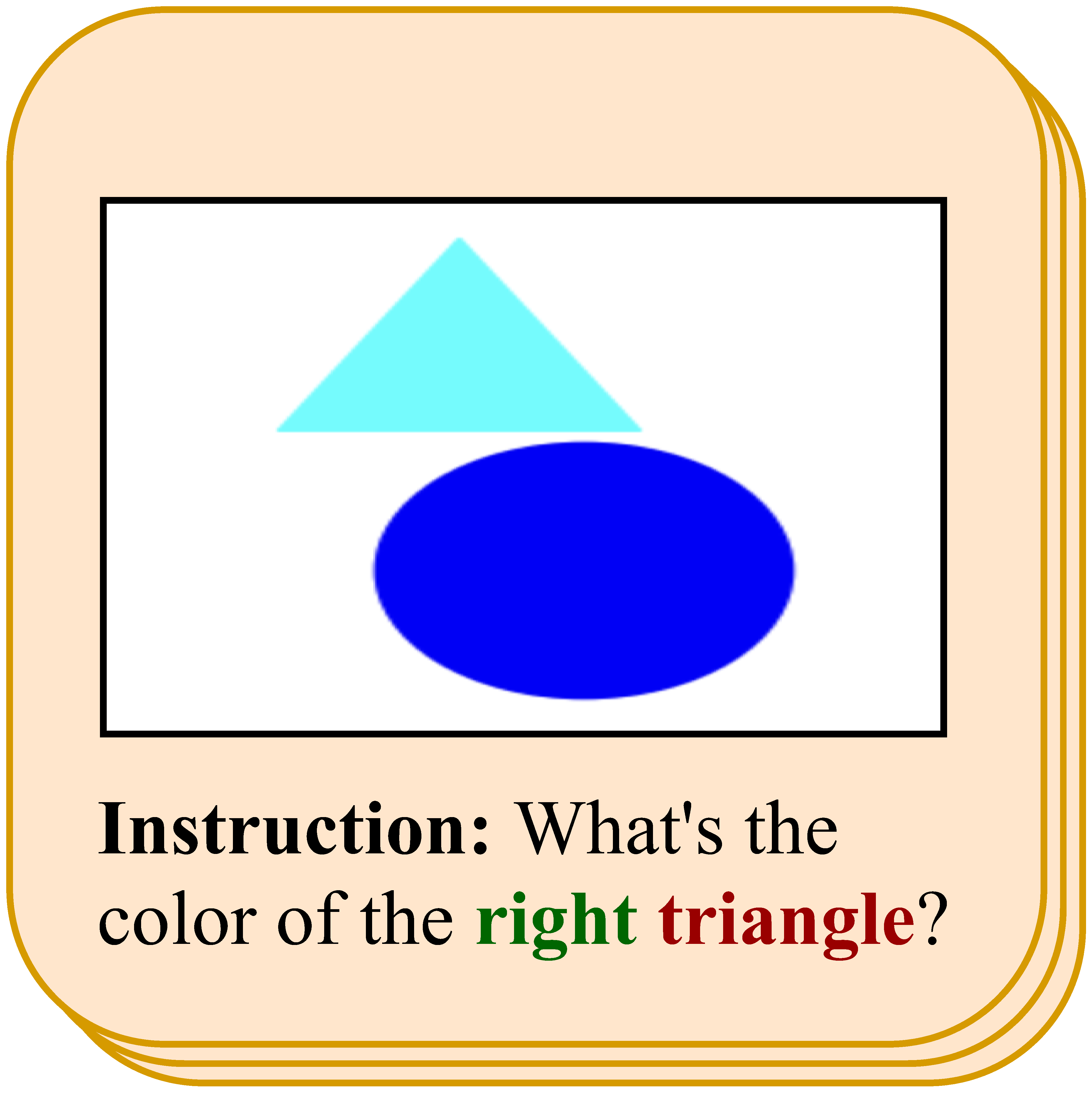

We propose AutoCreate, an automatic dataset creation framework that leverages programs and large language models. AutoCreate starts fromseveral task-relevant seeds and maintains a seed pool. During each cycle, AutoCreate includes two branches, the language (left) and the vision (right). Each branch consists of a generator and a decorator. Finally, the cleaner will exclude data that does not meet the standards. The data will be fed into the seed pool for the next round after aquality check by human experts.
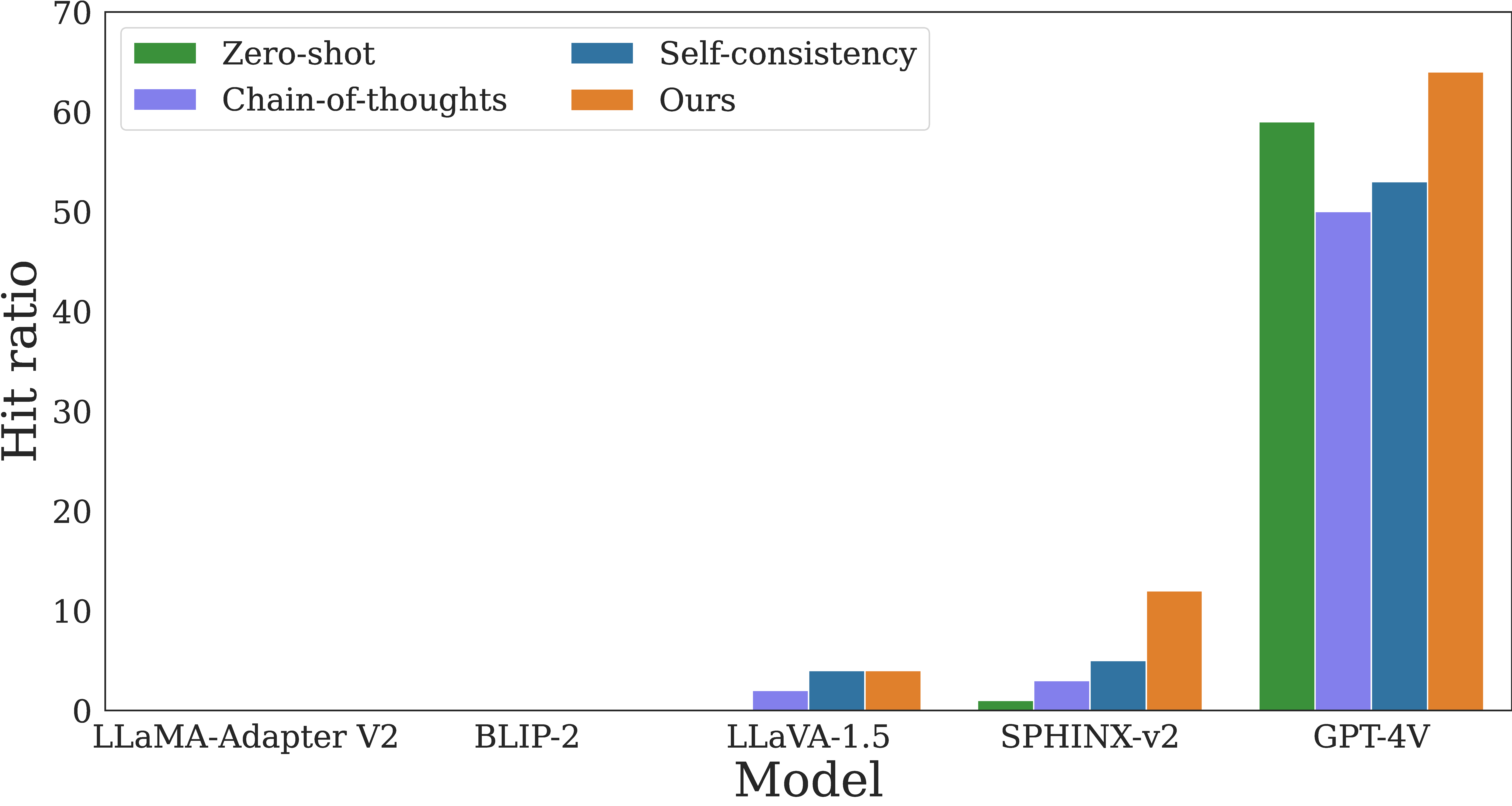
Our approach, Cognitive Awakening Prompting, improves LMMs' performance greatly. Chain-of-thoughts and self-consistency prompting bring limited improvement. Replies are evaluated by human experts for more precise results. It is also worth mentioning that, in our self-contradictory setting, these in-context learning skills sometimes fail to achieve the originally expected result, which could be the reason why they fail to improve performance on SCI. For example, "Please think step by step" is meant to elicit a chain of LMM thoughts but is sometimes deemed as a normal context to be translated, paraphrased, and summarized in OCRConflict.
@inproceedings{Gao2024dissecting,
title={Dissecting Dissonance: Benchmarking Large Multimodal Models Against Self-Contradictory Instructions},
author={Gao, Jin and Gan, Lei and Li, Yuankai and Ye, Yixin and Wang, Dequan},
booktitle={ECCV},
year={2024}
}